Hands on, hands off
Making the complex more simple
Snowplow do three things well. Data collection, data validation and decoupling of Events and Entities. What Snowplow has always struggled with is explaining these and through no fault of their own. These are some complex concepts. Once people understand them, they're sold. They're in! They LOVE Snowplow.
Getting users to understand all the complexities of Snowplow is very hands-on. It usually includes lots of support contact or onboarding from the Professional Services team. Sometimes onboarding can take months.
My role has made me responsible for making things simpler. Creating solutions to help us be more "self-serve" that would help promote product-led growth. In this article I will talk about some of the things I have done to make Snowplow successful.
What's a schema?
After joining Snowplow, I had ONE job... understanding everything. I set sail on a journey of education. This involved reading lots of articles, watching Gong videos and reading through the trenches of insights we had in Dovetail.
It also involved pestering some of my favourite Snowplowers. I asked lots of questions. Eventually, a lot of "a-ha" moments began to click into place.
I spent the first 6 months really without a Product Manager, so I had to do both roles for my first task.

Breaking the ice with a nice "easy" project
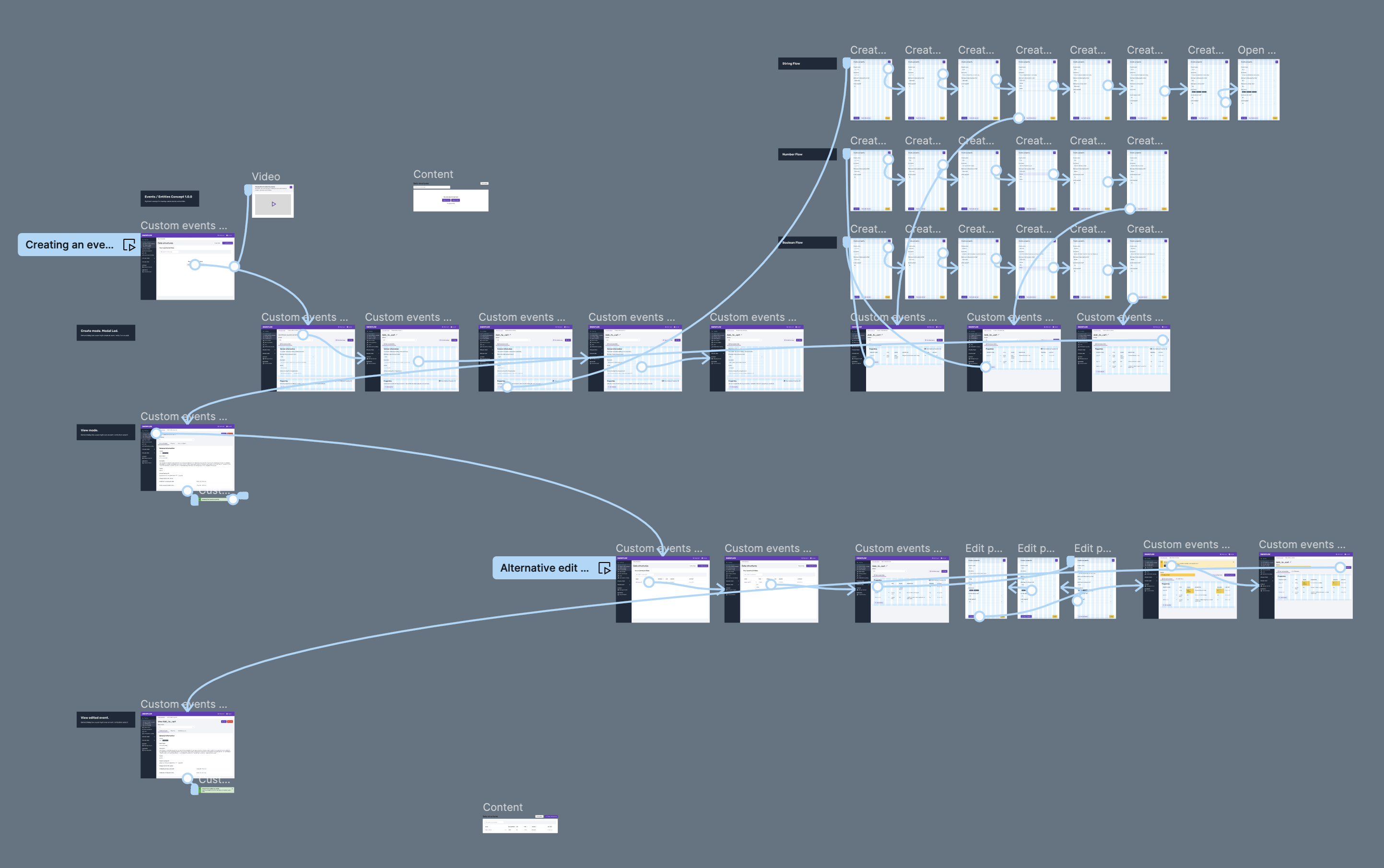
Creating custom data structures and evolving them over time is a key value proposition of Snowplow that we want to bring to BDP Cloud users. We believed that enabling BDP Cloud customers to create custom data structures is one of the key levers we could pull to shorten their time to value.
By general availability we wanted to enable customers to edit and customise their schemas according to their needs, as well as creating new custom events and entities from scratch.
The solution I would come up with would primarily solve an issue for BDP Cloud; if I would come up with a solution that is generalisable across both our self-serve and Enterprise option, well then; that would be even better.

I discovered through interviewing some existing customers and our subject matter experts was that Tracking Design and our current workflows for creating and evolving schemas were quite complex – even for users who have guidance from our Implementation team – so I would need to find ways to simplify this experience for BDP cloud users who will be largely on their own, supported only by documentation.
In addition, what I found was that most BDP Cloud customers will not have gone through the education of our extensive sales cycle, so they might lack context on key Snowplow concepts that we otherwise take for granted when creating design solutions for our Enterprise customers.
Setting acceptance criteria
I really needed to set some tight rules/goal posts around this project because I was starting to boil the ocean in my head. The acceptance criteria I set as a minimum were:
- As a BDP Cloud user I can create new event / entity schemas so that I can create data structured to my needs
- As a BDP Cloud user I can edit existing event / entity schemas so that I can evolve the structure of the data to meet my needs
- As a support engineer at Snowplow I want it to be difficult for BDP Cloud customers to break their data loading through bad schema versioning so that I don’t have to spend time fixing BDP Cloud pipelines
Hands tied behind my back
I had one thing that I really need to keep in mind. We won't be editing the underlying schema versioning logic. I had began to create a lot of discussion with engineers around the fact that the underlying schema logic may need a re-think. For now though, it's off the table. To be honest, it made it more of a challenge and I enjoyed this.
I also had a very niche target audience... BDP cloud customers. It could be assumed that they will:
- Have not had education provided by the sales cycle
- Have not had onboarding experience provided by Professional Services
- Be coming quite cold to the Snowplow tracking approach
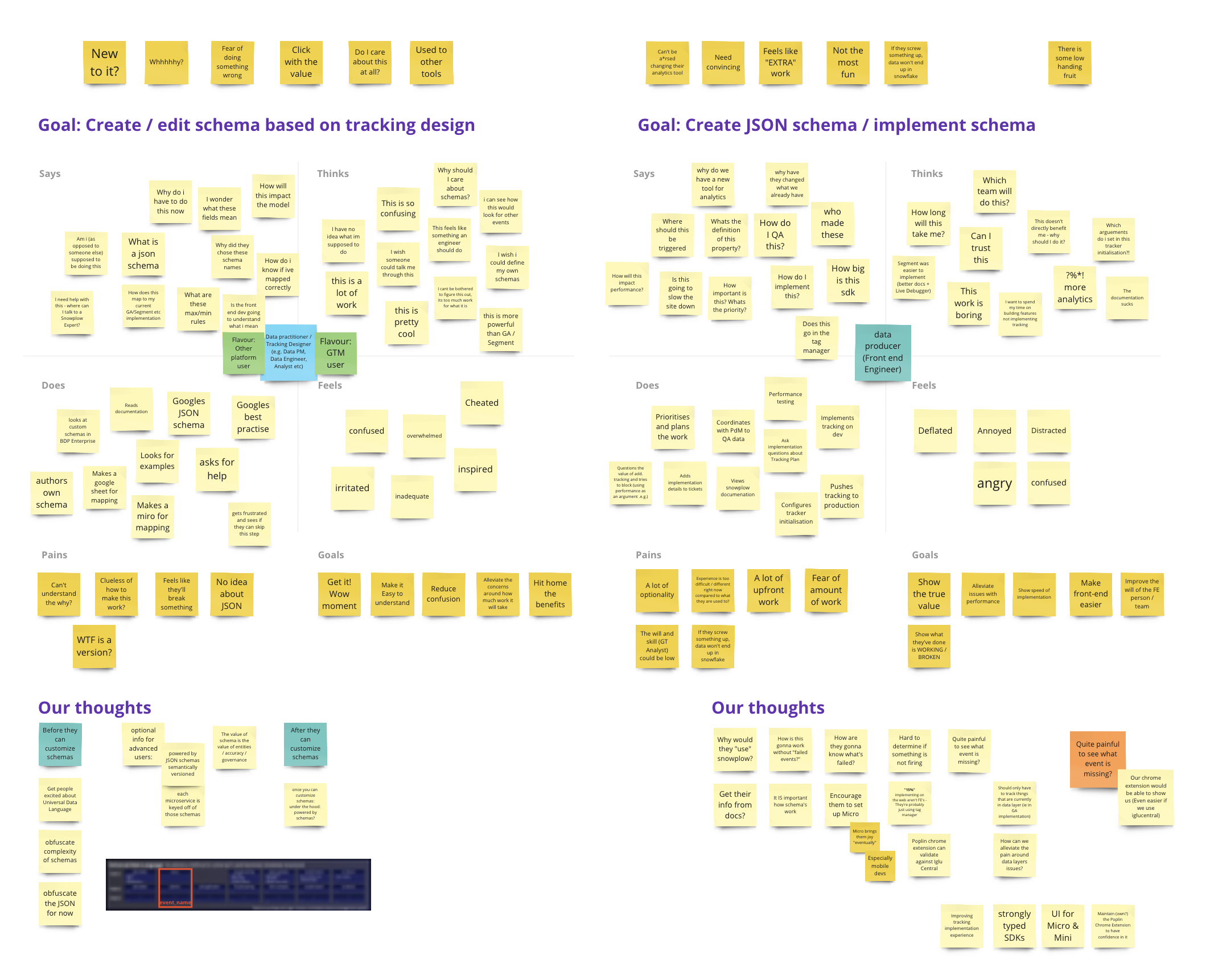
Empathy mapping with multiple personas
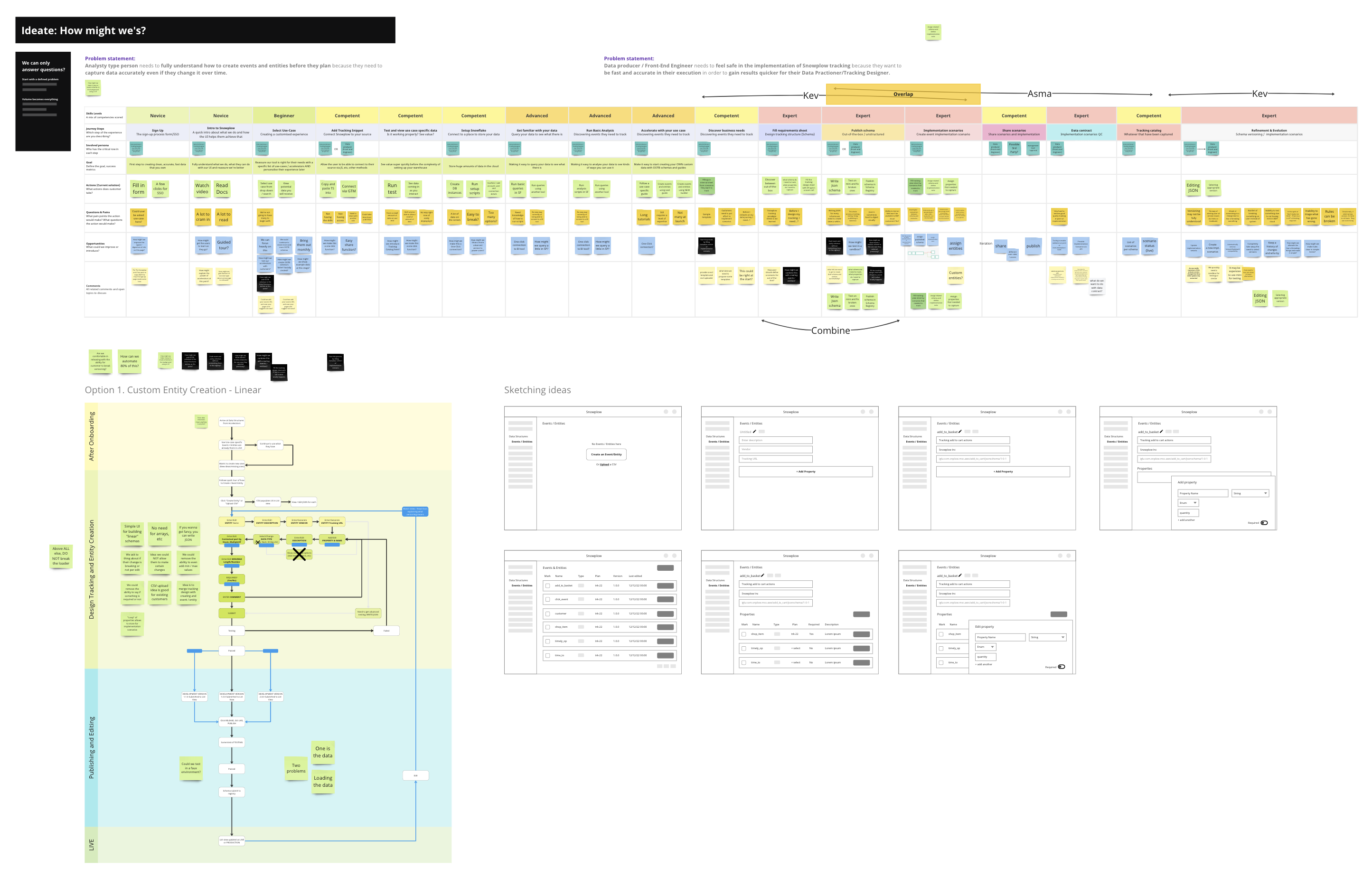
As well as the insights I gained from the interviews, I also ran an empathy map workshop with some internal stakeholders. I felt there was still more to learn from their educated views. We learned so much during that session and I created the following artefacts off the back of it.
They were:
- A flow for our private SASS offering mapped our in JIRA
- 3 initial experience maps with distinct ideas and options
- Assumptions map in Miro with some of the ideas we came up with
- An experience map that connected my chosen flow to the onboarding experience to see if there were gaps/pains
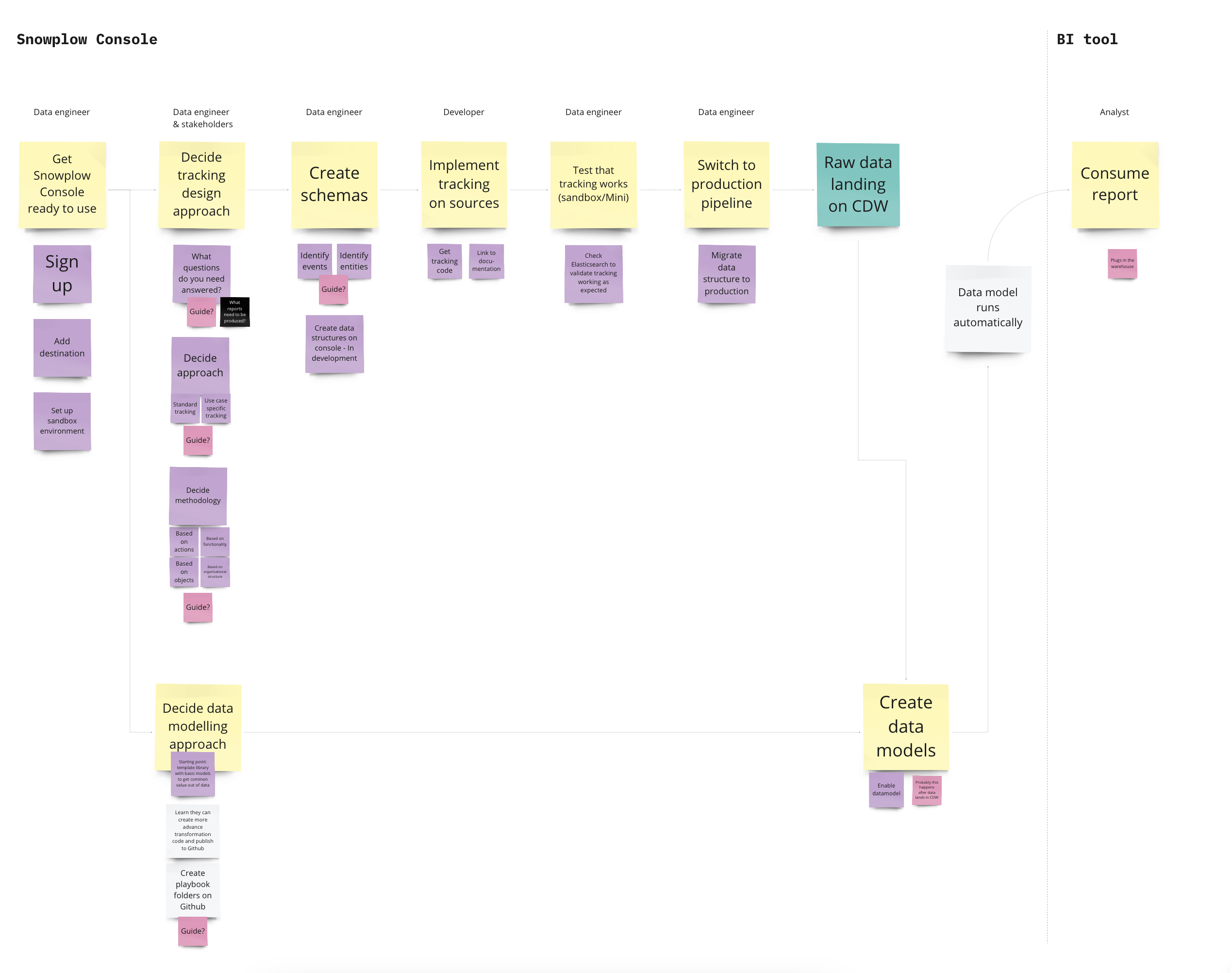
- A flow diagram explaining how versioning would fit-in with my new design
- Initial ideas and sketches from the chosen experience map how-might-we's.
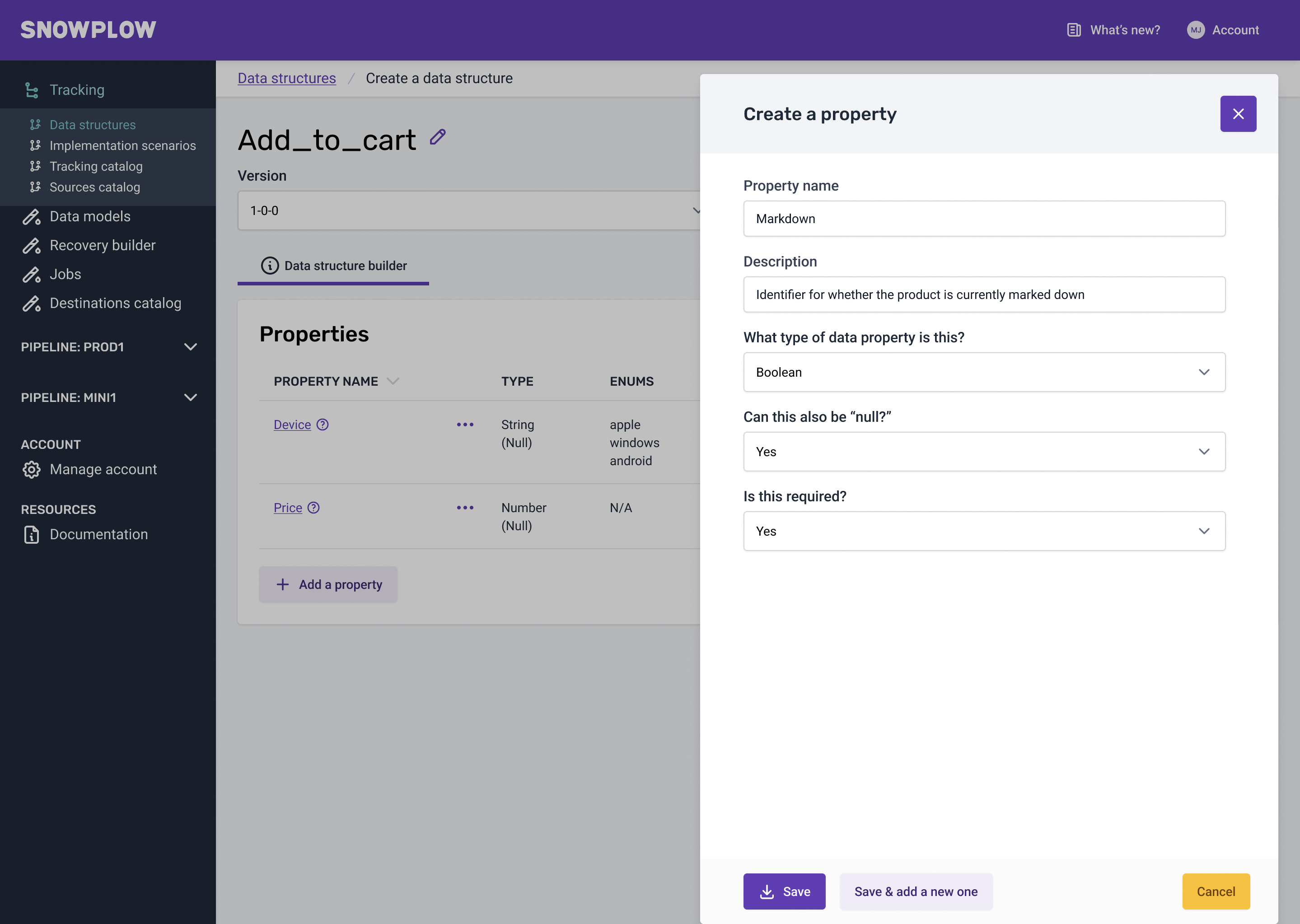
Out of all the problems to be solved, one big problem was being able to make writing JSON simple (without writing JSON). So the artefact that helped the most was the versioning flow. The "a-ha!" moment I got was that properties are just building blocks of a schema. People have tried to create JSON builders in the past and failed. They were all too cumbersome and writing JSON would be quicker.
What I did was treat properties as little building blocks encapsulated into a schema. This helped me come up with a design that was quick and repetitive.
I set up a meeting at this point with our dev team to add a sense check to some of my ideas. The feasibility of being able to detect a version change of a schema was the big one. They took the idea away and ran some experiments.
I designed a hi-fidelity prototype and tested it internally with our professional services team. After some feedback and once I ironed out some kinks, I delivered a final design to the dev team.
We built the MVP in 4 weeks and I began test with users. The feedback was overwhelmingly good.
A few quotes were:
"This will lower the bar and help my product team design tracking which I've wanted them to do for months"
"This is awesome"
"You mean I don't need to write JSON? I love this"
We did have some negative feedback about being unable to preview JSON while creating but we have since addressed this. The builder is currently still being used by 100s of users and I am very proud of my contribution.